Publications
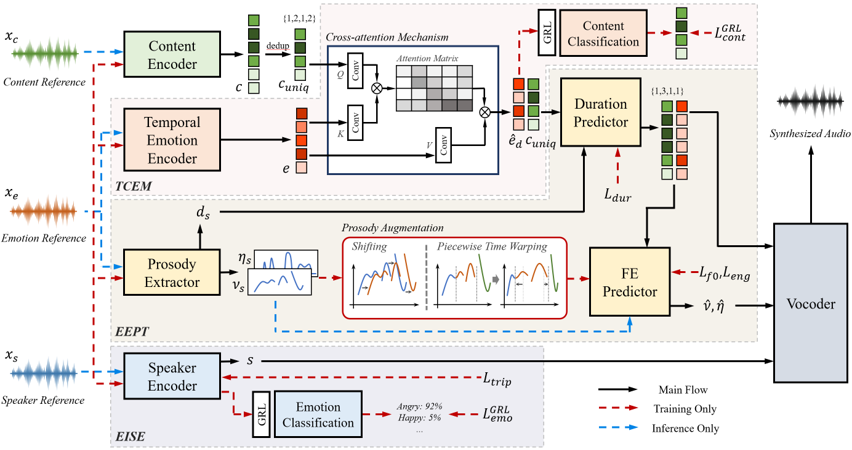
Maestro-EVC: Controllable Emotional Voice Conversion Guided by References and Explicit Prosody
Emotional voice conversion (EVC) aims to modify the emotional style of speech while preserving its linguistic content. In practical EVC, controllability, the ability to independently control speaker identity and emotional style using distinct references, is crucial. However, existing methods often struggle to fully disentangle these attributes and lack the ability to model fine-grained emotional expressions such as temporal dynamics. We propose Maestro-EVC, a controllable EVC framework that enables independent control of content, speaker identity, and emotion by effectively disentangling each attribute from separate references. We further introduce a temporal emotion representation and an explicit prosody modeling with prosody augmentation to robustly capture and transfer the temporal dynamics of the target emotion, even under prosody mismatched conditions. Experimental results confirm that Maestro-EVC achieves high-quality, controllable, and emotionally expressive speech synthesis.
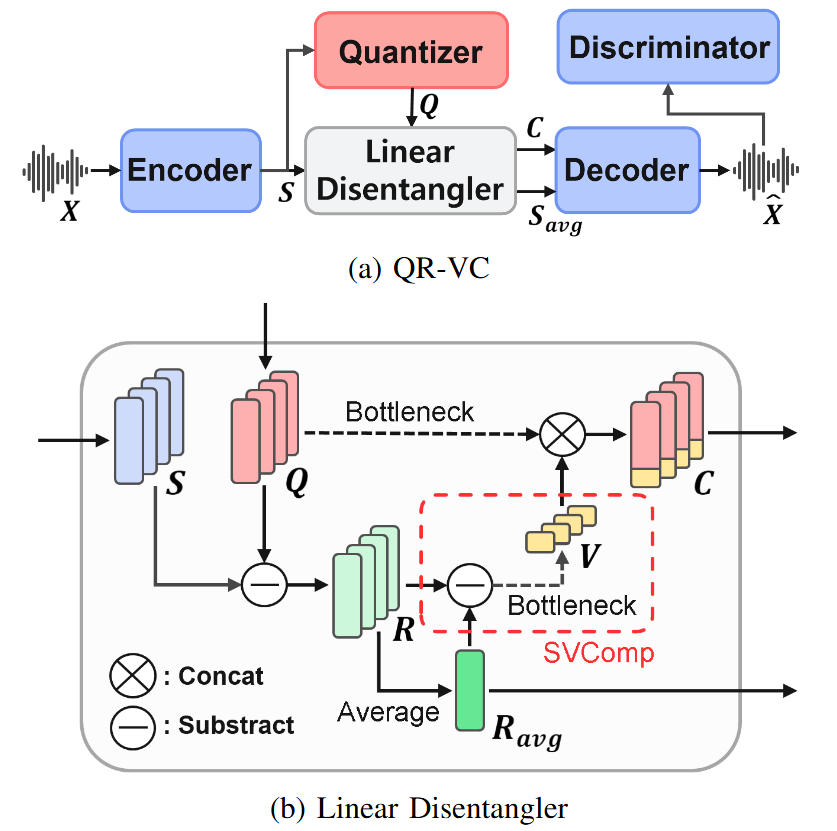
QR-VC: Leveraging Quantization Residuals for Linear Disentanglement in Zero-Shot Voice Conversion
Zero-shot voice conversion is a technique that alters the speaker identity of an input speech to match a target speaker using only a single reference utterance, without requiring additional training. Recent approaches extensively utilize self-supervised learning features with K-means quantization to extract high-quality content representations, effectively removing speaker identity by exploiting their structural properties. However, this quantization process also eliminates fine-grained phonetic and prosodic variations, leading to degradation in intelligibility and prosody preservation. While prior works have primarily focused on quantized representations, the potential of quantization residuals remains underexplored. In this paper, we introduce a novel approach that fully utilizes quantization residuals to disentangle speaker identity while restoring phonetic and prosodic details lost during quantization. By applying only K-means quantization and linear transformations, our method achieves effective disentanglement within a unified framework. This enables high-fidelity voice conversion while relying solely on reconstruction losses, eliminating the need for explicit supervision. Furthermore, it removes the reliance on complex, deep networks in the disentanglement structure. Experiments demonstrate that the proposed model outperforms existing methods while maintaining a simple disentanglement structure. It achieves superior intelligibility and speaker similarity while better preserving prosody, highlighting the impact of quantization residuals in zero-shot VC.
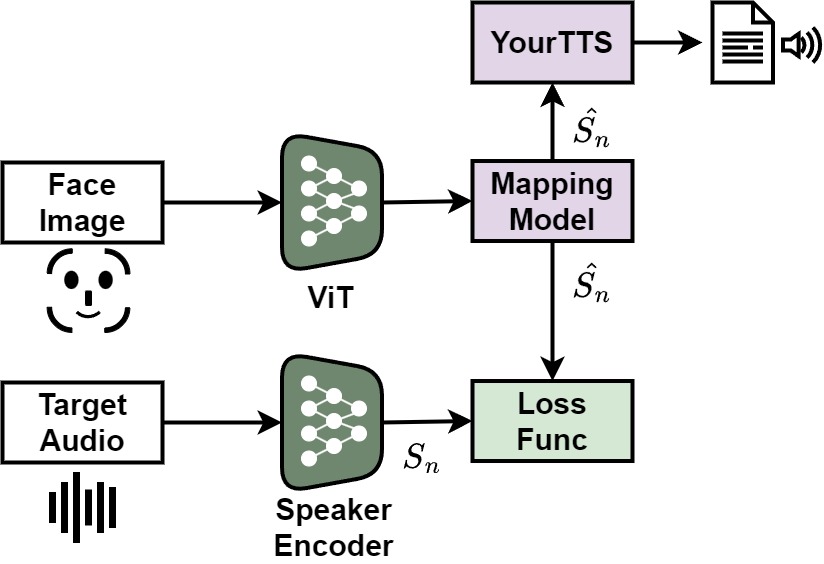
Speech Synthesis System Based on Speaker's Face Images
Most text-to-speech (TTS) and voice conversion (VC) systems synthesize utterance based on the voice of a specific speaker. To synthesize the voice of an unseen speaker during training, high-quality recordings are generally required. This paper proposes a system that estimates a speaker’s voice using low-resolution facial images and synthesizes natural-sounding speech based on this estimation. Experimental results demonstrate that the proposed system can synthesize speech with a naturalness close to that of the original speaker’s voice, while maintaining high consistency between the face and the voice.
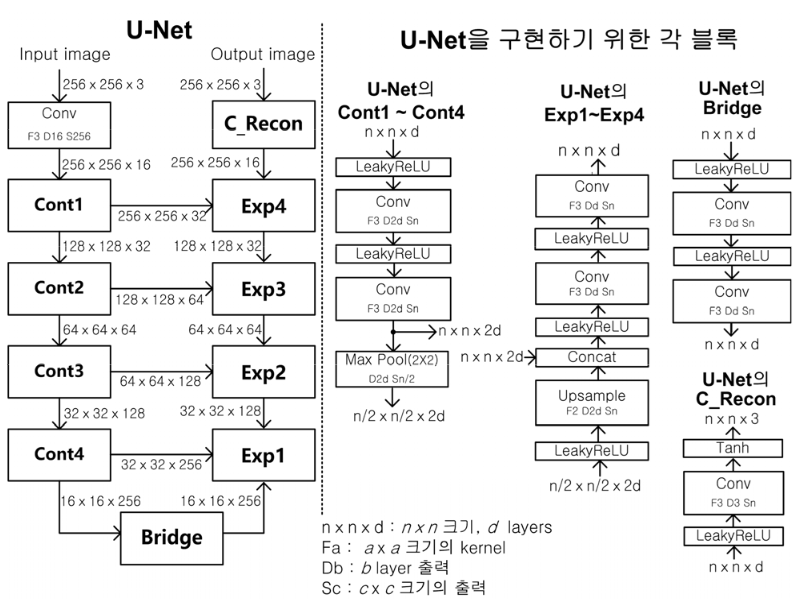
New U-Net for Image Deblurring Using Deep Learning
Many studies have been conducted for image deblurring, which is classified into non-blind and blind image deblurring techniques. Many iterative methods have been studied based on the maximum-a-posteriori (MAP) framework for image deblurring. Recently, deep learning methods for blind image deblurring have attracted a lot of attention for their excellent performance. In this paper, a method for improving the performance of the blind image deblurring using deep learning is proposed by introducing a new structure of U-Net. U-Net is used as a deep neural network for deep learning in various image processing fields. We propose a new U-Net by using short cut and parallel structure in each stage of contractive and expansive path for U-Net, and pre-processing and post-processing are used for the proposed new U-Net to improve the deblurring performance. Extensive computer simulations are performed to evaluate the image deblurring performance for motion blur and Gaussian blur, and it is shown that the proposed U-Net shows superior image deblurring performance compared to the conventional U-Net.